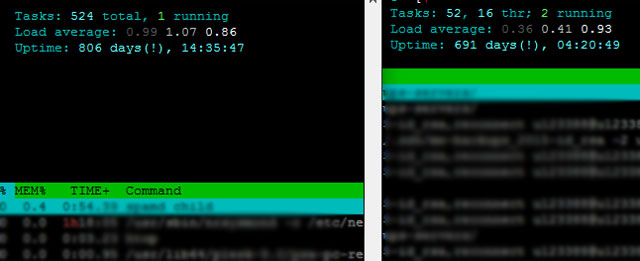
Otro título sugerido: Nunca entendí a los que presumen del uptime.
De cada 100 veces que un nerd consulta el uptime de una PC o server, 99 es para presumirle a otro nerd al respecto. El otro 1% es para ver si la PC o server se rebooteó mientras nadie la miraba.
Los nerds no presumen de quien la tiene mas larga, presumen de quien la tiene mas vieja y se sobre-entiende que si la tenés mas vieja, es por que automáticamente sos mas macho y por carácter transitivo además la tenés mas larga.
A mas proximidad con Linux, mayor aglomeración de nerds alrededor. Por eso no me asombró que Linux tuviera un comando para medir la longitud de un pito. Solamente hay que ejecutar uptime delante de tu grupo de amigos para demostrar tu hombría y que despejar cualquier duda sobre quien es el macho alfa. La próxima ronda de cervezas vos no pagás y todos brindan en tu honor.