A este le puse por título TIP por que no es mas que eso: otro ayuda memoria para la posteridad, a saber:
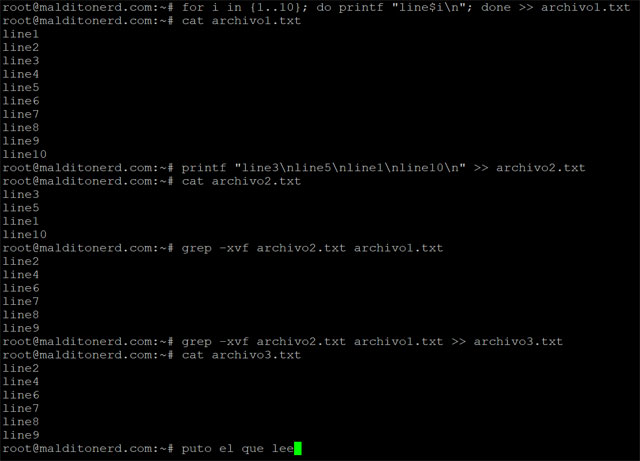
- Tenés dos archivos con texto: archivo1 y archivo2 como en el ejemplo de la captura de pantalla.
- Necesitás identificar las líneas duplicadas o simplemente restarlas como en el ejemplo y mostrar únicamente las que no se repiten.
La única forma que conozco de lograr esto en Bash sin recurrir a complicados regex de la muerte forma mas rápida de lograr esto sin tener que pensar mucho es como tantas otras veces: GREP. Alguien debería hacerle un pedestal al autor original de grep, sin duda.
Los switchs que vas a utilizar en grep son:
- -x match únicamente si toda la línea coincide.
- -f para en lugar de utilizar stdin o una palabra como argumento, usar un archivo, de a una línea por vez.
- -v para reverse search, restar las líneas que coincidan en archivo2 de archivo1.
Utilizar grep en Bash para restar el contenido de un archivo de otro linea a linea en la consola de comando de Linux
Entonces para el ejemplo de mas arriba o si tienen ganas de jugar al Bash un ratito, primero generar un archivo conteniendo diez líneas distintas:
for i in {1..10}; do printf "line$i\n"; done >> archivo1.txt
Generar luego un segundo archivo conteniendo cuatro líneas de texto que se repitan en ambos:
printf "line3\nline5\nline1\nline10\n" >> archivo2.txt
Ahora si, como se hace:
Disponiendo ahora de los dos archivos del banco de pruebas, sólo queda eliminar las líneas que se repitan en ambos archivos:
[email protected]:~# grep -xvf archivo2.txt archivo1.txt
line2
line4
line6
line7
line8
line9
Otro caso de utilidad podría ser el ejemplo inverso, match únicamente las líneas que coincidan en ambos archivo, indistintamente del orden en que se encuentren, tomando como base el contenido de archivo2 y comparándolo con archivo1 (eliminando -v para el reverse match).
[email protected]:~# grep -xf archivo2.txt archivo1.txt
line1
line3
line5
line10
¿Te sirvió? De nada.